Automated HR data anonymization is the process of irreversibly removing any information that identifies an employee from a document or database. This definition is not only technical. It directly affects your compliance with the GDPR and your exposure to sanctions. For HR professionals and compliance managers, anonymize HR data automated processing today represents a management obligation, not an option. The European Data Protection Board (EDPS) sets specific criteria, and breaches expose the organization to fines of up to €20 million or 4% of global turnover.
How to anonymize HR data with automated processing?
Before any implementation, you must precisely identify which data falls within the scope to be processed. Sensitive HR data covers a wide spectrum: names, social security numbers, addresses, health data, performance evaluations, disciplinary information and banking data. Each category obeys distinct storage rules.
Legal durations vary depending on the type of document. The Unsuccessful CVs must be anonymized or deleted a maximum of 2 years after the last contact with the candidate. Payroll documents, on the other hand, can be kept for up to 50 years. This asymmetry forces HR teams to segment their automated processing by documentary category, and not to apply a single rule.
Prior documentation is a legal obligation, not a formality. The automated anonymization process itself constitutes processing subject to the GDPR, which means that it requires an identified legal basis and an updated record of processing activities. Here are the essential prerequisites before deploying automated processing:
- Data mapping: list all personal fields present in the HRIS, HR files and archived documents.
- Classification by sensitivity: distinguish ordinary data from data of a particular nature (health, origin, beliefs).
- Definition of retention periods: associate each category with its legal duration and program the corresponding deletions or anonymization.
- Documented legal basis: formalize the legal justification for the processing in the GDPR register.
- Impact analysis (AIPD): carry out an impact analysis if the processing is likely to generate a high risk for the rights of individuals.
What techniques and tools can automate HR anonymization?
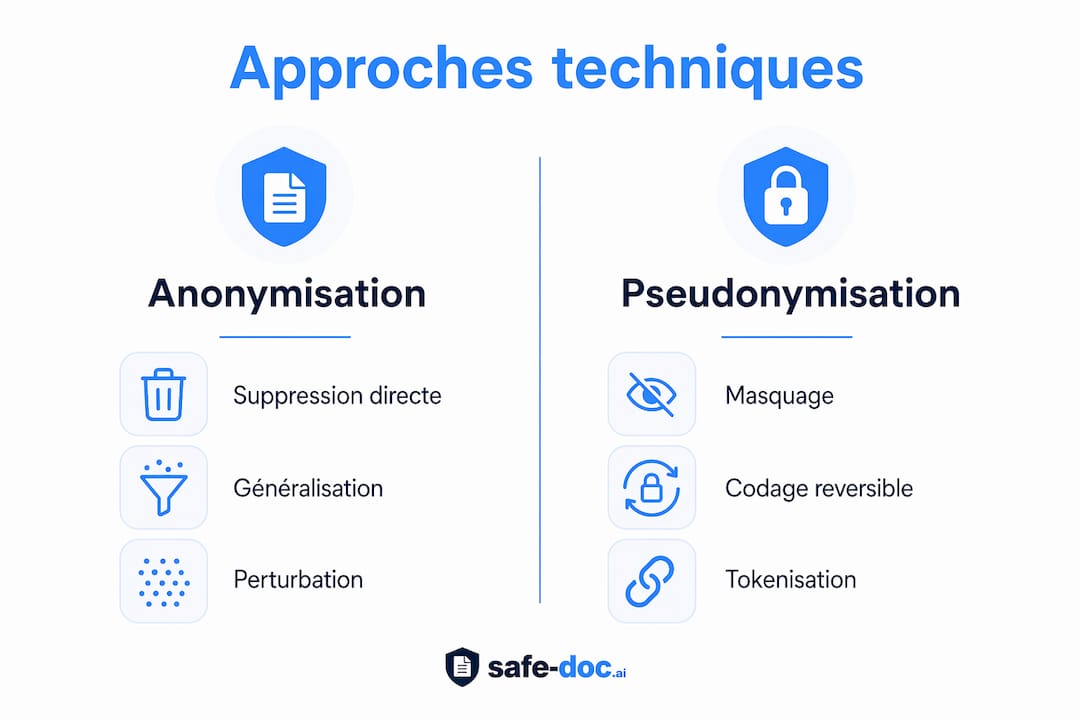
Anonymization vs. pseudonymization: a distinction that changes everything
The legal irreversibility of anonymization allows data to be taken out of the scope of the GDPR. Pseudonymization remains under strict regulation because the link with the person can be reestablished. In practice, most companies confuse these two concepts. Pseudonymization is often preferable in daily HR: it maintains a useful link between data while reducing exposure. Understanding this distinction between anonymization and pseudonymization is the starting point for any HR data protection strategy.
The main technical approaches
Automated scripts and named entity detection (NER) tools guarantee more reliable anonymization than manual processing, particularly on large documentary volumes. NER technology automatically identifies names, places, dates and identifiers in text and then replaces or deletes them. This approach reduces the risk of human forgetting, which is the primary cause of incomplete anonymization.

| Technical | Principle | Main advantage | Main limit |
|---|---|---|---|
| Direct deletion | Clearing identifier fields | Simple to implement | Loss of analytical value |
| Generalization | Replacement with a less precise value (e.g.: age → age range) | Preserves statistical utility | Residual risk of re-identification |
| Pseudonymization | Substitution by a reversible fictitious identifier | Link kept for internal use | Stays under GDPR |
| Automated NER | AI named entity detection and processing | Large-scale processing | Requires business configuration |
| Aggregation | Grouping in collective statistics | No individual data exposed | Not usable for individual folders |
Pro tip: Combine NER detection with a human validation rule on a 5% sample of processed documents. This spot check detects parameterization errors before they propagate throughout the corpus.
How to integrate automated anonymization into existing HR processes?
Integration into an existing HRIS follows a logic of successive layers. It does not replace existing workflows. It works with it to trigger automatic actions at specific moments in the data life cycle.
Here are the steps of a structured integration:
1. Map document flows: identify when each type of document enters the HRIS, who accesses it and when it should be archived or deleted.
2. Configure automatic triggers: configure rules that activate anonymization at the legal deadline (end of contract, retention period reached, closure of a recruitment file).
3. Implement access control: restrict access to data not yet anonymized to authorized people only, with logging of each consultation.
4. Enable Audit Trail: the integration of anonymization into HRIS includes filing, access control, audit trail and scheduled deletion to ensure compliance and traceability.
5. Maintain human intervention: article 22 of the GDPR prohibits any exclusively automated HR decision without significant human intervention. A manager must validate sensitive decisions resulting from automated processing.
6. Document each step: record processing parameters, execution dates and processed volumes in the GDPR register.
Access management deserves particular attention. A document being anonymized remains personal data in its own right. Access must be limited to what is strictly necessary for the duration of treatment. Once anonymization has been validated, the document leaves the GDPR scope and can be treated as ordinary data.
What challenges and mistakes should you avoid during automated anonymization?
The most common risks
Imperfect anonymization is the main risk. A document may appear anonymized on the surface but contain combinations of residual data that allow a person to be re-identified. For example, the combination of position, department and date of hire may be enough to identify an individual in a small organization.
- Forgetting indirect fields: file metadata (author, creation date) often contain personal information that basic tools do not process.
- Partial anonymization: process the body of a document without processing attachments or headers.
- No re-evaluation: anonymization must be regularly reassessed because external bases and algorithms evolve, which can compromise the initial robustness of a treatment.
- Undetected algorithmic biases: algorithmic bias auditing is essential to prevent AI from recreating discriminatory correlations despite anonymization of input data.
- Non-compliance of the process itself: forget that anonymization, as long as it is not completed, remains a processing subject to the GDPR.
Technically successful anonymization may become legally insufficient if external reidentification techniques progress. The robustness of a treatment must be reassessed at least once a year, or at each significant change in the analysis tools available on the market.
Compliance continues as a discipline
Anonymization compliance is not a state. This is a regular practice. The EDPS criteria for true anonymization cover three dimensions: resistance to individualization, correlation and inference. A treatment that meets these three criteria at the time of its implementation may no longer meet them two years later if external analysis capabilities have progressed. Planning annual audits of the system is a good governance practice, not an additional constraint.
Key points
Automated anonymization of HR data requires a combination of validated NER techniques, rigorous documentation, and regular reassessment to remain GDPR compliant.
| Item | Details |
|---|---|
| Mandatory EDPS criteria | Anonymization must resist individualization, correlation and inference to escape the GDPR field. |
| Variable shelf life | CVs are kept for a maximum of 2 years; payroll documents can be up to 50 years old depending on regulations. |
| NER for large volumes | Automatic named entity detection reduces human oversights and ensures consistent processing at scale. |
| Mandatory human intervention | Article 22 of the GDPR prohibits exclusively automated HR decisions without meaningful human validation. |
| Annual reassessment essential | Reidentification techniques are evolving; a treatment that is compliant today may no longer be compliant in 18 months. |
What field experience reveals about HR anonymization
By Jacques
After years of supporting HR teams on compliance projects, I notice a recurring error: confusing pseudonymization with complete anonymization, then believing that the work is finished. This is not an error in bad faith. This is a mistake in understanding the legal framework, and it is costly.
The reality that I observe in the field is that pseudonymization is often the best operational response for HR. It makes it possible to maintain a link between data for internal management needs, while reducing exposure. Complete anonymization applies to permanently archived data, aggregated statistics or datasets transmitted to third parties. Mixing the two approaches in the same process without clearly distinguishing them creates legal gray areas that are difficult to defend before the CNIL.
What concerns me more is the lack of governance over time. Many organizations deploy an anonymization tool, configure it once, and then never evaluate it again. However, reidentification capabilities are progressing every year. Robust treatment in 2023 may be insufficient in 2026. The real discipline is regular auditing, not initial deployment.
Automation remains the best protection against human error on large volumes. But it does not exempt you from a rigorous governance with regular audits. The two are complementary, not substitutable.
— Jacques
Safe-doc to automatically anonymize your HR data
HR teams that process large volumes of employee files need a tool that takes action before the data reaches an external AI model. Safe-doc meets this need by pseudonymizing sensitive documents in real time, without ever storing them.
Safe-doc uses Named Entity Detection (NER) to automatically identify and hide personal information in HR records, contracts, appraisals and pay slips. The processing integrates into your existing workflows without changing your work habits. HR and DPO professionals therefore have a GDPR-compliant layer of protection, with a zero-storage architecture that ensures that no sensitive data passes to third-party servers. Compliance becomes an ongoing process, not a box to check.
Frequently asked questions
What is the anonymization of HR data according to the GDPR?
HR data anonymization is the process of irreversibly removing any information that could identify an employee. Once anonymized, the data falls outside the scope of the GDPR according to the EDPS criteria.
What is the difference between anonymization and pseudonymization in HR?
Pseudonymization replaces identifiers with reversible codes and remains subject to the GDPR. Anonymization permanently removes the link with the person and frees the data from any regulatory obligation linked to the protection of personal data.
How does NER detection work to anonymize HR documents?
NER technology automatically scans text to identify names, dates, addresses and identifiers, then replaces or deletes them. It processes large volumes of documents in a homogeneous manner, which significantly reduces the risk of forgetting compared to manual processing.
Does Article 22 of the GDPR apply to automated HR processing?
Yes. Article 22 of the GDPR prohibits any exclusively automated HR decision without significant human intervention. This applies to hiring, evaluation, or firing decisions produced by an algorithm without human validation.
How often should an automated anonymization system be re-evaluated?
An anonymization system must be re-evaluated at least once a year. Reidentification techniques are evolving, and processing deemed sufficient when deployed may become insufficient if external analysis capabilities progress.