L’anonymisation automatisée des données RH est le processus qui supprime de façon irréversible toute information permettant d’identifier un employé dans un document ou une base de données. Cette définition n’est pas seulement technique. Elle conditionne directement votre conformité au RGPD et votre exposition aux sanctions. Pour les professionnels RH et les responsables de conformité, anonymiser données rh traitement automatisé représente aujourd’hui une obligation de gestion, pas une option. Le Comité Européen de la Protection des Données (CEPD) fixe des critères précis, et les manquements exposent l’organisation à des amendes pouvant atteindre 20 millions d’euros ou 4 % du chiffre d’affaires mondial.
Comment anonymiser données RH avec un traitement automatisé ?
Avant toute mise en œuvre, vous devez identifier précisément quelles données entrent dans le périmètre à traiter. Les données RH sensibles couvrent un spectre large : noms, numéros de sécurité sociale, adresses, données de santé, évaluations de performance, informations disciplinaires et données bancaires. Chaque catégorie obéit à des règles de conservation distinctes.
Les durées légales varient selon le type de document. Les CV non retenus doivent être anonymisés ou supprimés au maximum 2 ans après le dernier contact avec le candidat. Les documents de paie, en revanche, peuvent être conservés jusqu’à 50 ans. Cette asymétrie oblige les équipes RH à segmenter leurs traitements automatisés par catégorie documentaire, et non à appliquer une règle unique.
La documentation préalable est une obligation légale, pas une formalité. Le processus d’anonymisation automatisée constitue lui-même un traitement soumis au RGPD, ce qui signifie qu’il nécessite une base légale identifiée et un registre des activités de traitement mis à jour. Voici les prérequis indispensables avant de déployer un traitement automatisé :
- Cartographie des données : lister tous les champs personnels présents dans le SIRH, les fichiers RH et les documents archivés.
- Classification par sensibilité : distinguer les données ordinaires des données à caractère particulier (santé, origine, convictions).
- Définition des durées de conservation : associer chaque catégorie à sa durée légale et programmer les suppressions ou anonymisations correspondantes.
- Base légale documentée : formaliser la justification juridique du traitement dans le registre RGPD.
- Analyse d’impact (AIPD) : réaliser une analyse d’impact si le traitement est susceptible de générer un risque élevé pour les droits des personnes.
Quelles techniques et outils permettent d’automatiser l’anonymisation RH ?
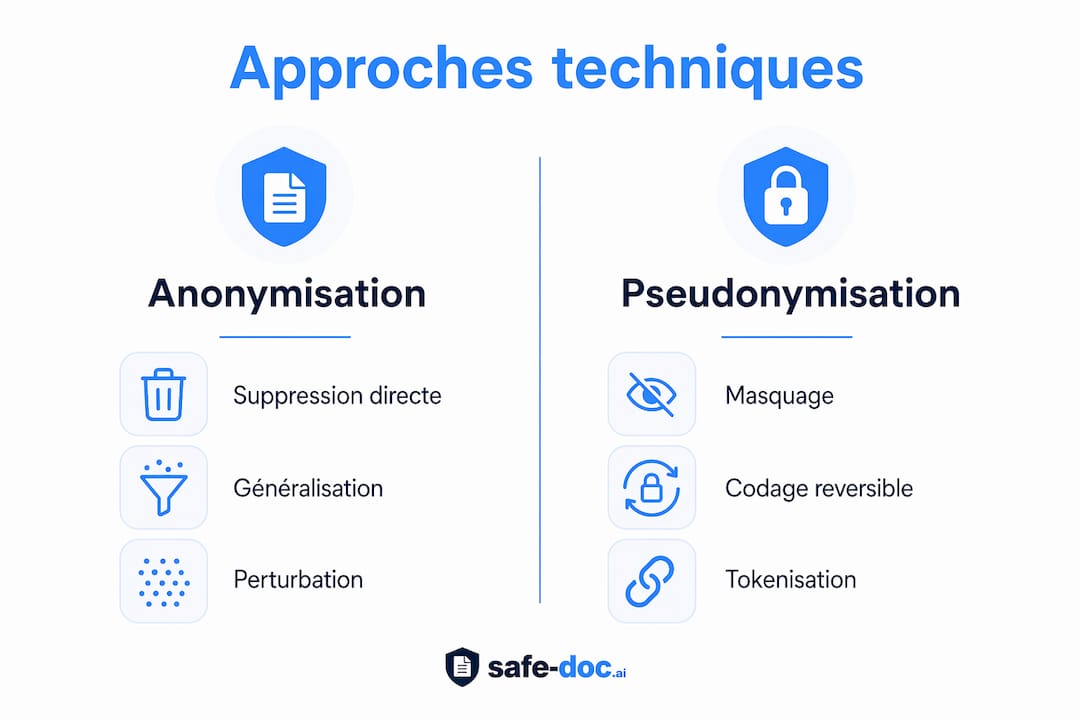
Anonymisation vs pseudonymisation : une distinction qui change tout
L’irréversibilité juridique de l’anonymisation permet de sortir les données du champ du RGPD. La pseudonymisation, elle, reste sous réglementation stricte car le lien avec la personne peut être rétabli. En pratique, la plupart des entreprises confondent ces deux notions. La pseudonymisation est souvent préférable au quotidien RH : elle conserve un lien utile entre les données tout en réduisant l’exposition. Comprendre cette distinction entre anonymisation et pseudonymisation est le point de départ de toute stratégie de protection des données RH.
Les principales approches techniques
Les scripts automatisés et les outils de détection d’entités nommées (NER) garantissent une anonymisation plus fiable qu’un traitement manuel, particulièrement sur de grands volumes documentaires. La technologie NER identifie automatiquement les noms, lieux, dates et identifiants dans un texte, puis les remplace ou les supprime. Cette approche réduit le risque d’oubli humain, qui est la première cause d’anonymisation incomplète.

| Technique | Principe | Avantage principal | Limite principale |
|---|---|---|---|
| Suppression directe | Effacement des champs identifiants | Simple à implémenter | Perte de valeur analytique |
| Généralisation | Remplacement par une valeur moins précise (ex. : âge → tranche d’âge) | Préserve l’utilité statistique | Risque résiduel de réidentification |
| Pseudonymisation | Substitution par un identifiant fictif réversible | Lien conservé pour usage interne | Reste sous RGPD |
| NER automatisé | Détection et traitement des entités nommées par IA | Traitement à grande échelle | Nécessite un paramétrage métier |
| Agrégation | Regroupement en statistiques collectives | Aucune donnée individuelle exposée | Inutilisable pour les dossiers individuels |
Conseil de pro: Combinez la détection NER avec une règle de validation humaine sur un échantillon de 5 % des documents traités. Cette vérification ponctuelle détecte les erreurs de paramétrage avant qu’elles ne se propagent à l’ensemble du corpus.
Comment intégrer l’anonymisation automatisée dans les processus RH existants ?
L’intégration dans un SIRH existant suit une logique de couches successives. Elle ne remplace pas les workflows en place. Elle s’y greffe pour déclencher des actions automatiques à des moments précis du cycle de vie des données.
Voici les étapes d’une intégration structurée :
- Cartographier les flux documentaires : identifier à quel moment chaque type de document entre dans le SIRH, qui y accède et quand il doit être archivé ou supprimé.
- Configurer les déclencheurs automatiques : paramétrer des règles qui activent l’anonymisation à l’échéance légale (fin de contrat, délai de conservation atteint, clôture d’un dossier de recrutement).
- Mettre en place le contrôle d’accès : restreindre l’accès aux données non encore anonymisées aux seules personnes habilitées, avec journalisation de chaque consultation.
- Activer la piste d’audit : l’intégration de l’anonymisation dans les SIRH inclut le classement, le contrôle d’accès, la piste d’audit et la suppression programmée pour assurer conformité et traçabilité.
- Maintenir l’intervention humaine : l’article 22 du RGPD interdit toute décision RH exclusivement automatisée sans intervention humaine significative. Un responsable doit valider les décisions sensibles issues d’un traitement automatisé.
- Documenter chaque étape : consigner les paramètres de traitement, les dates d’exécution et les volumes traités dans le registre RGPD.
La gestion des accès mérite une attention particulière. Un document en cours d’anonymisation reste une donnée personnelle à part entière. L’accès doit être limité au strict nécessaire pendant toute la durée du traitement. Une fois l’anonymisation validée, le document sort du périmètre RGPD et peut être traité comme une donnée ordinaire.
Quels défis et erreurs éviter lors de l’anonymisation automatisée ?
Les risques les plus fréquents
L’anonymisation imparfaite est le risque principal. Un document peut sembler anonymisé en surface mais contenir des combinaisons de données résiduelles qui permettent de réidentifier une personne. Par exemple, la combinaison poste occupé, département et date d’embauche peut suffire à identifier un individu dans une petite structure.
- Oubli de champs indirects : les métadonnées de fichiers (auteur, date de création) contiennent souvent des informations personnelles que les outils basiques ne traitent pas.
- Anonymisation partielle : traiter le corps d’un document sans traiter les pièces jointes ou les en-têtes.
- Absence de réévaluation : l’anonymisation doit être régulièrement réévaluée car les bases externes et les algorithmes évoluent, ce qui peut compromettre la robustesse initiale d’un traitement.
- Biais algorithmiques non détectés : l’audit de biais algorithmique est indispensable pour éviter que l’IA ne recrée des corrélations discriminatoires malgré l’anonymisation des données d’entrée.
- Non-conformité du processus lui-même : oublier que l’anonymisation, tant qu’elle n’est pas achevée, reste un traitement soumis au RGPD.
Une anonymisation techniquement réussie peut devenir juridiquement insuffisante si les techniques de réidentification externes progressent. La robustesse d’un traitement doit être réévaluée au minimum une fois par an, ou à chaque évolution significative des outils d’analyse disponibles sur le marché.
La conformité continue comme discipline
La conformité en matière d’anonymisation n’est pas un état. C’est une pratique régulière. Les critères du CEPD pour une anonymisation véritable couvrent trois dimensions : résistance à l’individualisation, à la corrélation et à l’inférence. Un traitement qui satisfait ces trois critères au moment de sa mise en place peut ne plus les satisfaire deux ans plus tard si les capacités d’analyse externe ont progressé. Planifier des audits annuels du dispositif est une bonne pratique de gouvernance, pas une contrainte supplémentaire.
Points clés
L’anonymisation automatisée des données RH exige une combinaison de techniques NER validées, d’une documentation rigoureuse et d’une réévaluation régulière pour rester conforme au RGPD.
| Point | Détails |
|---|---|
| Critères CEPD obligatoires | L’anonymisation doit résister à l’individualisation, à la corrélation et à l’inférence pour sortir du champ RGPD. |
| Durées de conservation variables | Les CV se conservent 2 ans maximum ; les documents de paie peuvent aller jusqu’à 50 ans selon la réglementation. |
| NER pour les grands volumes | La détection automatique d’entités nommées réduit les oublis humains et garantit un traitement homogène à grande échelle. |
| Intervention humaine obligatoire | L’article 22 du RGPD interdit les décisions RH exclusivement automatisées sans validation humaine significative. |
| Réévaluation annuelle indispensable | Les techniques de réidentification évoluent ; un traitement conforme aujourd’hui peut ne plus l’être dans 18 mois. |
Ce que l’expérience terrain révèle sur l’anonymisation RH
Par Jacques
Après des années à accompagner des équipes RH sur des projets de conformité, je constate une erreur récurrente : confondre la pseudonymisation avec l’anonymisation complète, puis croire que le travail est terminé. Ce n’est pas une erreur de mauvaise foi. C’est une erreur de compréhension du cadre juridique, et elle coûte cher.
La réalité que j’observe sur le terrain est que la pseudonymisation est souvent la meilleure réponse opérationnelle pour les RH. Elle permet de conserver un lien entre les données pour les besoins de gestion interne, tout en réduisant l’exposition. L’anonymisation complète, elle, s’applique aux données archivées définitivement, aux statistiques agrégées ou aux jeux de données transmis à des tiers. Mélanger les deux approches dans un même processus sans les distinguer clairement crée des zones grises juridiques difficiles à défendre devant la CNIL.
Ce qui me préoccupe davantage, c’est l’absence de gouvernance dans le temps. Beaucoup d’organisations déploient un outil d’anonymisation, le paramètrent une fois, puis ne le réévaluent jamais. Or les capacités de réidentification progressent chaque année. Un traitement robuste en 2023 peut être insuffisant en 2026. La vraie discipline, c’est l’audit régulier, pas le déploiement initial.
L’automatisation reste la meilleure protection contre l’erreur humaine sur les grands volumes. Mais elle ne dispense pas d’une gouvernance rigoureuse avec audits réguliers. Les deux sont complémentaires, pas substituables.
— Jacques
Safe-doc pour anonymiser automatiquement vos données RH
Les équipes RH qui traitent des volumes importants de dossiers salariés ont besoin d’un outil qui agit avant que les données n’atteignent un modèle d’IA externe. Safe-doc répond à ce besoin en pseudonymisant les documents sensibles en temps réel, sans jamais les stocker.
Safe-doc utilise la détection d’entités nommées (NER) pour identifier et masquer automatiquement les informations personnelles dans les dossiers RH, contrats, évaluations et bulletins de paie. Le traitement s’intègre dans vos flux existants sans changer vos habitudes de travail. Les professionnels RH et DPO disposent ainsi d’une couche de protection conforme au RGPD, avec une architecture zéro stockage qui garantit qu’aucune donnée sensible ne transite vers des serveurs tiers. La conformité devient un processus continu, pas une case à cocher.
Questions fréquentes
Qu’est-ce que l’anonymisation des données RH selon le RGPD ?
L’anonymisation des données RH est le processus qui supprime de façon irréversible toute information permettant d’identifier un employé. Une fois anonymisées, les données sortent du champ d’application du RGPD selon les critères du CEPD.
Quelle est la différence entre anonymisation et pseudonymisation en RH ?
La pseudonymisation remplace les identifiants par des codes réversibles et reste soumise au RGPD. L’anonymisation supprime définitivement le lien avec la personne et libère les données de toute obligation réglementaire liée à la protection des données personnelles.
Comment fonctionne la détection NER pour anonymiser des documents RH ?
La technologie NER analyse automatiquement le texte pour identifier les noms, dates, adresses et identifiants, puis les remplace ou les supprime. Elle traite de grands volumes de documents de façon homogène, ce qui réduit significativement les risques d’oubli par rapport à un traitement manuel.
L’article 22 du RGPD s’applique-t-il aux traitements RH automatisés ?
Oui. L’article 22 du RGPD interdit toute décision RH exclusivement automatisée sans intervention humaine significative. Cela s’applique aux décisions d’embauche, d’évaluation ou de licenciement produites par un algorithme sans validation humaine.
À quelle fréquence faut-il réévaluer un dispositif d’anonymisation automatisée ?
Un dispositif d’anonymisation doit être réévalué au minimum une fois par an. Les techniques de réidentification évoluent, et un traitement jugé suffisant lors de son déploiement peut devenir insuffisant si les capacités d’analyse externe progressent.